



Stale zwiększająca się ilość danych gromadzonych w firmach budzi nadzieję na odkrycie nowych, nieznanych dotąd zależności. Przetwarzanie dużych, nieustrukturyzowanych zbiorów wymaga stosowania wydajnych rozwiązań, które będą w stanie je odpowiednio procesować.
| REKLAMA | ||
 |
Dużą zmianą było wprowadzenie koncepcji MapReduce, która jest używana przez wiele narzędzi wchodzących w skład ekosystemu Hadoop. Polega ona na wykorzystaniu wielu node’ów (komputerów), z których każdy odpowiedzialny jest za przetwarzanie mniejszej części całego zbioru danych. Obliczenia rozproszone szybko zyskały na popularności. Hadoop 1.0, który ujrzał światło dzienne 27 grudnia 2011 roku był jedną z pierwszych platform wykorzystywanych do przetwarzania dużych zbiorów danych w trybie batchowym. Rozwiązanie miało umożliwić przetwarzanie terabajtów danych, przy czym mogło to trwać godzinami, a nawet dniami.
Z biegiem lat potrzeby biznesowe zaczęły ewoluować, a technologia musiała iść naprzód, by sprostać stawianym przed nią nowym wyzwaniom. Oprócz zdolności do przetwarzania dużych zbiorów danych, zaczęto zauważać korzyści z procesowania ich w trybie rzeczywistym. Stwarza to znacznie większe możliwości, ponieważ dynamicznie zmieniające się uwarunkowania biznesowe wymagają szybszego dostępu do danych.
Pojawiło się wiele projektów umożliwiających pozyskiwanie i przetwarzanie danych w trybie rzeczywistym – np. Apache Kafka czy Spark Streaming. Podstawowym problemem pozostał brak wystarczającej wydajności, umożliwiającej dostatecznie szybkie przetwarzanie nie tylko napływających, nowych danych, ale również posiadanego już historycznego zbioru.
Chcąc przezwyciężyć te problemy powstało wiele koncepcji architektonicznych, które umożliwiają połączenie korzyści wynikających z przetwarzania danych w trybie batchowym, jak i w trybie real-time. Najczęściej wykorzystywane są koncepcje Lambda oraz Kappa.
Definicje pojęcia real-time
Pojęcie real time jest definiowane różnorodnie – często bardziej marketingowo niż w rzeczywistości. Można przyjąć następującą klasyfikację:
Z biegiem lat potrzeby biznesowe zaczęły ewoluować, a technologia musiała iść naprzód, by sprostać stawianym przed nią nowym wyzwaniom. Oprócz zdolności do przetwarzania dużych zbiorów danych, zaczęto zauważać korzyści z procesowania ich w trybie rzeczywistym. Stwarza to znacznie większe możliwości, ponieważ dynamicznie zmieniające się uwarunkowania biznesowe wymagają szybszego dostępu do danych.
Pojawiło się wiele projektów umożliwiających pozyskiwanie i przetwarzanie danych w trybie rzeczywistym – np. Apache Kafka czy Spark Streaming. Podstawowym problemem pozostał brak wystarczającej wydajności, umożliwiającej dostatecznie szybkie przetwarzanie nie tylko napływających, nowych danych, ale również posiadanego już historycznego zbioru.
Chcąc przezwyciężyć te problemy powstało wiele koncepcji architektonicznych, które umożliwiają połączenie korzyści wynikających z przetwarzania danych w trybie batchowym, jak i w trybie real-time. Najczęściej wykorzystywane są koncepcje Lambda oraz Kappa.
Definicje pojęcia real-time
Pojęcie real time jest definiowane różnorodnie – często bardziej marketingowo niż w rzeczywistości. Można przyjąć następującą klasyfikację:
- Macro batch >= 15 minut
- Micro batch - >2 minuty ale < 15 minut
- Near Real Time Decision Support - >=2 sekundy i <2 minut
- Near Real Time Event Processing - > 50 ms i <2 sekund
- Real Time < 50ms
W ekosystemie Big Data istnieje do dyspozycji wiele narzędzi, które można do tego celu wykorzystać. Są one przedstawione na grafice 1:
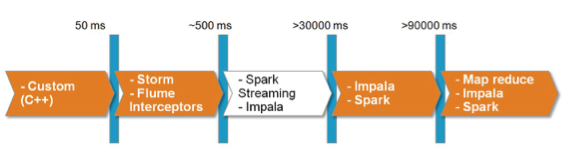
Grafika 1: Przykładowe narzędzia z ekosystemu Big Data służące do przetwarzania danych w zależności od szybkości ich napływania.
Architektura Lambda
Zapewnienie równoległego przetwarzania dużych, nieustrukturyzowanych zbiorów danych oraz zapewnienia do nich nieustannego dostępu w czasie rzeczywistym możliwe jest poprzez zastosowanie architektury Lambda.
Założenie polega na stworzeniu dwóch osobnych przepływów, gdzie jeden odpowiedzialny jest za przetwarzanie danych w trybie wsadowym, natomiast drugi za dostęp do nich w trybie rzeczywistym. Stale napływający strumień danych kierowany jest do obu warstw.
Architektura Lambda została zobrazowana na grafice 2.
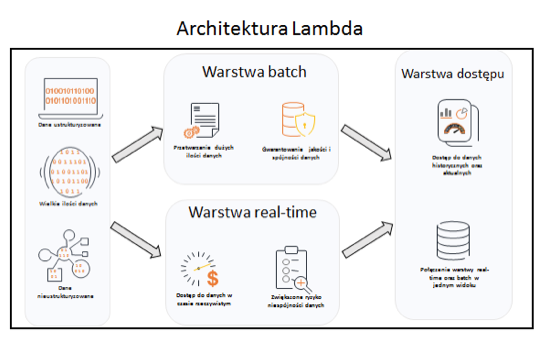
Grafika 2: Schemat architektury Lambda.
W warstwie batch obliczenia wykonywane są na całym zbiorze danych. Odbywa się to kosztem czasu, ale otrzymane w zamian dane zawierają pełną historię i wysoką jakość. Zakłada się, że zbiór danych znajdujący się w warstwie batch ma formę niepodzielną, którą należy jedynie rozszerzać, aniżeli usuwać z niej dane. W ten sposób można zapewnić pełną historyzację i spójność danych.
Warstwa real-time przetwarza napływające dane w trybie rzeczywistym. Oferuje ona niski czas dostępu do danych, co przekłada się na możliwość szybszego pozyskania informacji. Niestety, brak dostępu do danych historycznych sprawia, że nie wszystkie obliczenia są możliwe do wykonania. Często jakość oraz wiarygodność danych pochodzących z warstwy real time nie jest tak wysoka, jak z warstwy batch. Te drugie należy uważać za bardziej wiarygodne, ale ze względu na dłuższy czas potrzebny na ich załadowanie, warstwa real-time okazuje się nieocenioną pomocą, chcąc zagwarantować możliwość przetwarzania danych w trybie rzeczywistym.
Warstwa dostępu jest miejscem, w którym tworzone są widoki na podstawie warstwy batch oraz real-time. Dane są agregowane w taki sposób, aby końcowy użytkownik widział je jako jedną, spójną całość, aniżeli dwa niezależne, całkiem odrębne systemy. Widoki powinny być przygotowane w taki sposób, aby zapewnić możliwość wykonywania wszelkiego rodzaju analiz ad-hoc, ciesząc się przy tym szybkim dostępem do danych.
Koncepcja architektury Lambda zapewnia wiele zalet, przede wszystkim doskonały kompromis między przetwarzaniem wsadowym i real-time. Największą i najczęściej wspominaną wadą jest konieczność utrzymywania dwóch niezależnych aplikacji – jednej do zasilania warstwy batch, natomiast drugiej do warstwy real-time. Narzędzia wykorzystywane w poszczególnych warstwach różnią się między sobą, więc ciężko jest dobrać jedno, które może być wykorzystane do dwóch celów. Jest to możliwe w przypadku Apache Spark, gdzie po zdefiniowaniu logiki, według której dane mają być przetwarzane, można ją wywołać w trybie batchowym, jak i w trybie Spark Streaming, który ze strumienia danych wejściowych tworzy tzw. micro-batch i pozwala na przetwarzanie ich w czasie niemalże rzeczywistym.
Architektura Kappa
W roku 2014 Jay Kreps w swoim blogu wprowadził termin architektury Kappa jako odpowiedź na krytykę związaną z implementacją oraz utrzymaniem systemów opartych o architekturę Lambda. Nowa architektura została oparta o cztery główne założenia:
Grafika 1: Przykładowe narzędzia z ekosystemu Big Data służące do przetwarzania danych w zależności od szybkości ich napływania.
Architektura Lambda
Zapewnienie równoległego przetwarzania dużych, nieustrukturyzowanych zbiorów danych oraz zapewnienia do nich nieustannego dostępu w czasie rzeczywistym możliwe jest poprzez zastosowanie architektury Lambda.
Założenie polega na stworzeniu dwóch osobnych przepływów, gdzie jeden odpowiedzialny jest za przetwarzanie danych w trybie wsadowym, natomiast drugi za dostęp do nich w trybie rzeczywistym. Stale napływający strumień danych kierowany jest do obu warstw.
Architektura Lambda została zobrazowana na grafice 2.
Grafika 2: Schemat architektury Lambda.
W warstwie batch obliczenia wykonywane są na całym zbiorze danych. Odbywa się to kosztem czasu, ale otrzymane w zamian dane zawierają pełną historię i wysoką jakość. Zakłada się, że zbiór danych znajdujący się w warstwie batch ma formę niepodzielną, którą należy jedynie rozszerzać, aniżeli usuwać z niej dane. W ten sposób można zapewnić pełną historyzację i spójność danych.
Warstwa real-time przetwarza napływające dane w trybie rzeczywistym. Oferuje ona niski czas dostępu do danych, co przekłada się na możliwość szybszego pozyskania informacji. Niestety, brak dostępu do danych historycznych sprawia, że nie wszystkie obliczenia są możliwe do wykonania. Często jakość oraz wiarygodność danych pochodzących z warstwy real time nie jest tak wysoka, jak z warstwy batch. Te drugie należy uważać za bardziej wiarygodne, ale ze względu na dłuższy czas potrzebny na ich załadowanie, warstwa real-time okazuje się nieocenioną pomocą, chcąc zagwarantować możliwość przetwarzania danych w trybie rzeczywistym.
Warstwa dostępu jest miejscem, w którym tworzone są widoki na podstawie warstwy batch oraz real-time. Dane są agregowane w taki sposób, aby końcowy użytkownik widział je jako jedną, spójną całość, aniżeli dwa niezależne, całkiem odrębne systemy. Widoki powinny być przygotowane w taki sposób, aby zapewnić możliwość wykonywania wszelkiego rodzaju analiz ad-hoc, ciesząc się przy tym szybkim dostępem do danych.
Koncepcja architektury Lambda zapewnia wiele zalet, przede wszystkim doskonały kompromis między przetwarzaniem wsadowym i real-time. Największą i najczęściej wspominaną wadą jest konieczność utrzymywania dwóch niezależnych aplikacji – jednej do zasilania warstwy batch, natomiast drugiej do warstwy real-time. Narzędzia wykorzystywane w poszczególnych warstwach różnią się między sobą, więc ciężko jest dobrać jedno, które może być wykorzystane do dwóch celów. Jest to możliwe w przypadku Apache Spark, gdzie po zdefiniowaniu logiki, według której dane mają być przetwarzane, można ją wywołać w trybie batchowym, jak i w trybie Spark Streaming, który ze strumienia danych wejściowych tworzy tzw. micro-batch i pozwala na przetwarzanie ich w czasie niemalże rzeczywistym.
Architektura Kappa
W roku 2014 Jay Kreps w swoim blogu wprowadził termin architektury Kappa jako odpowiedź na krytykę związaną z implementacją oraz utrzymaniem systemów opartych o architekturę Lambda. Nowa architektura została oparta o cztery główne założenia:
- Wszystko jest strumieniem – strumień stanowi nieskończoną ilość skończonych paczek danych (batchów). Stąd każdy rodzaj zasilania danymi może być uważany za strumień.
- Dane są niezmienne (immutable) – dane surowe są persystowane w oryginalnej postaci i nie zmieniają się, dzięki czemu w każdej chwili można ich użyć ponownie.
- Reguła KISS – Keep is short and simple. W tym przypadku przez użycie wyłącznie jednego silnika do analizy danych zamiast kilku, jak w przypadku architektury Lambda.
- Możliwość odtworzenia stanu danych – kalkulacje i ich rezultaty mogą być odświeżane przez odtwarzanie danych historycznych i aktualnych bezpośrednio z tego samego strumienia danych w każdym momencie.
Krytyczne dla powyższych reguł jest zapewnienie niezmiennej i oryginalnej kolejności danych w strumieniu. Bez spełnienia tego warunku nie jest możliwe uzyskanie konsystentnych (deterministycznych) wyników obliczeń.
Opisane zasady dotyczące architektury Kappa zostały zobrazowane na grafice 3. Od razu rzuca się w oczy uproszczenie względem architektury Lambda:
Grafika 3: Schemat architektury Kappa.
Podobnie jak w architekturze Lambda mamy warstwę Real-Time i warstwę Dostępu, które pełnią tutaj te same funkcje. Natomiast brak jest warstwy Batch, która stała się zbędna ponieważ historię można w każdej chwili odtworzyć ze strumienia danych w warstwie Dostępu przy pomocy identycznego silnika przetwarzania danych.
Autorzy:
Dawid Benski – lat 34, Starszy Architekt działu Insights & Data w firmie Capgemini Software Solutions Center. we Wrocławiu. Posiada 7 lat doświadczenia w projektach bazodanowych i Business Intelligence oraz 3 lata doświadczenia w projektach Big Data.
Michał Dura – lat 25, Inżynier Oprogramowania w dziale Insights & Data w firmie Capgemini Software Solutions Center. we Wrocławiu. Posiada 2 lata doświadczenia w projektach Big Data.
